spark on yarn
By
yuanxiaolong
更新日期:
介绍如何让 spark 跑在 yarn 上
spark 可以单独部署,用自带的资源管理器,也支持在 yarn 上运行. 本文介绍 spark streaming on yarn client mode
环境准备
- hadoop集群
- 在每个节点上下载spark 1.4.0 的tar包并解压
- 在 /etc/profile 下设置 YARN_CONF_DIR 以便能够让 spark 提交任务的时候读取到 yarn 的 ResourceManager 地址后申请资源
- kafka 0.8.2.1
- scala 2.10.5
工程搭建概述
sbt 和 maven scala插件都可以创建 spark job 任务,本质上还是打成了一个 jar 包。本文介绍的是 spark streaming on yarn ,因为spark更适合处理实时流的任务
如果是离线计算就交给hadoop吧
这里有篇文章 官网介绍(虽然是 spark 1.1.0 但实际上代码是兼容的,目前我跑在 1.4.0 上没有问题) https://spark.apache.org/docs/1.1.0/streaming-programming-guide.html
这里介绍sbt工程需要注意的地方:
- build.sbt: 构建依赖管理文件,其中的scalaVersion需与安装的scala版本一致
- assembly.sbt: 打包成jar包时,执行策略
- plugins.sbt:用于添加仓库地址或插件
assembly.sbt
1
2
3
4
5
6
| //一般来说还会有log4j冲突的问题,添加下面解决
case "log4j.properties" => MergeStrategy.first
case x if x.contains("org/apache/commons/logging") => MergeStrategy.last
//这里指定了入口函数
mainClass in assembly := Some("com.myproject.main.Main")
|
build.sbt
像一些jar包可能 maven 仓库没有 就需要从本地添加
- spark-streaming_2.10-1.1.0.jar
- spark-sql_2.10-1.1.0.jar
- spark-core_2.10-1.1.0.jar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import sbt.Keys._
name := "Jinx"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-streaming_2.10" % "1.1.0" % "provided" from "file://" + baseDirectory.value + "/src/main/spark-lib/spark-streaming_2.10-1.1.0.jar"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.1.0" % "provided" from "file://" + baseDirectory.value + "/src/main/spark-lib/spark-core_2.10-1.1.0.jar"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "1.1.0" % "provided" from "file://" + baseDirectory.value + "src/main/spark-lib/spark-sql_2.10-1.1.0.jar"
libraryDependencies ++= Seq(
("org.apache.hadoop" % "hadoop-common" % "2.3.0").exclude("commons-httpclient", "commons-httpclient"),
("org.apache.hadoop" % "hadoop-hdfs" % "2.3.0").exclude("commons-httpclient", "commons-httpclient"),
("org.apache.hadoop" % "hadoop-yarn" % "2.3.0").exclude("commons-httpclient", "commons-httpclient"),
("org.apache.hadoop" % "hadoop-yarn-client" % "2.3.0").exclude("commons-httpclient", "commons-httpclient"),
("org.apache.hadoop" % "hadoop-client" % "2.3.0").exclude("commons-httpclient", "commons-httpclient")
)
libraryDependencies += "org.slf4j" % "slf4j-api" % "1.7.2"
libraryDependencies +=
"org.slf4j" % "slf4j-log4j12" % "1.7.2" excludeAll(
ExclusionRule(organization = "log4j")
)
libraryDependencies += "com.typesafe.akka" % "akka-actor_2.10" % "2.3.9"
libraryDependencies += ("org.apache.httpcomponents" % "httpclient" % "4.3.2")
libraryDependencies += ("net.sf.json-lib" % "json-lib" % "2.3" classifier "jdk15")
.exclude("commons-collections", "commons-collections")
libraryDependencies ++= Seq("com.twitter" %% "util-collection" % "6.23.0",
"com.twitter" % "util-eval_2.10" % "6.25.0")
libraryDependencies ++= Seq("org.mortbay.jetty" % "jetty" % "6.1.26",
"org.mortbay.jetty" % "servlet-api" % "2.5-20081211",
"org.mortbay.jetty" % "jetty-util" % "6.1.25")
libraryDependencies +=
"log4j" % "log4j" % "1.2.16" excludeAll(
ExclusionRule(organization = "com.sun.jdmk"),
ExclusionRule(organization = "com.sun.jmx"),
ExclusionRule(organization = "javax.jms")
)
libraryDependencies ++= Seq(
"net.debasishg" %% "redisclient" % "3.0"
)
name :="myproject-Jinx-Stream"
organization :="com.myorg"
version :="0.0.1-SNAPSHOT"
|
其中运行的较核心的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import org.apache.commons.lang.StringUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
import scala.collection.mutable.Map
val sparkConf = new SparkConf().setAppName("myTest")
.set("spark.yarn.jar","hdfs://hadoop3:8020/share/spark-assembly-1.4.0-hadoop2.3.0.jar")
.set("spark.yarn.historyServer.address", "http://hadoop3:18080")
.set("spark.yarn.access.namenodes", "hdfs://hadoop3:8032")
ssc = new StreamingContext(sparkConf, Seconds(60))
val topicMap = topics.split(",").map((_, 5)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
lines.foreachRDD(rdd =>{
println("---begin---")
println("---end---")
})
ssc.start()
ssc.awaitTermination()
|
启动
sbt clean assembly 打好的jar包在 target/scala-2.10/jinx-spark.jar- 启动
1
2
3
4
5
| export YARN_CONF_DIR=/etc/hadoop/conf/ && nohup /opt/app/spark-1.4.0-bin-hadoop2.3/bin/spark-submit \
--class com.myproject.main.Main \
--master yarn-client \
--num-executors 5 \
/data/jenkins/workspace/Jinx/target/scala-2.10/jinx-spark.jar >> /data/jenkins/workspace/Jinx/jinx-run.log &
|
关闭
- 先找到 yarn 上运行的任务
yarn application -list | grep <keyword>
yarn application -kill <$applicationId> 关闭掉 yarn应用、执行器- 在部署机器上
kill -9 $pid 关闭掉 spark driver
其中jenkins 可以做sbt项目的CI
我的开发环境脚本如下,可以参考 (记着jenkins 需要设置参数化构建 BUILD_ID=dontKillMe 不然出于保护原因,是不允许后台运行 jenkins所产生的进程的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #!/usr/bin/env bash
YARN_ID=`yarn application -list | grep MyTest | awk '{print $1}'`
for yid in $YARN_ID
do
echo "kill yarn $yid"
yarn application -kill $yid
done
ID=`ps -ef | grep 'jinx-spark.jar' | awk '{print $2}'`
for id in $ID
do
echo "kill process $id"
kill -9 $id
done
export YARN_CONF_DIR=/etc/hadoop/conf/
cp /data/jenkins/workspace/Jinx/target/scala-2.10/jinx-spark.jar /data/workspace/jinx
cd /data/workspace/jinx
nohup /opt/app/spark-1.4.0-bin-hadoop2.3/bin/spark-submit --class com.myproject.main.Main --master yarn-client --num-executors 5 /data/jenkins/workspace/Jinx/target/scala-2.10/jinx-spark.jar >> /data/jenkins/workspace/Jinx/jinx-run.log 2>&1 &
|
可能会遇到的问题
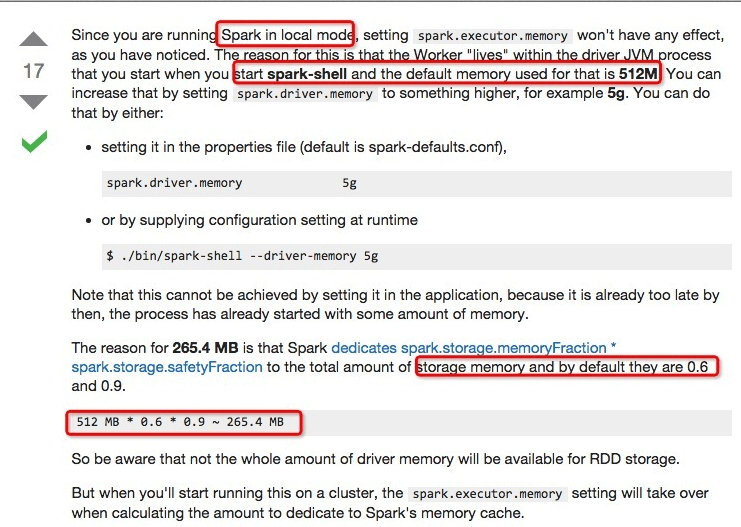
内存OOM,适当加大 driver 程序的内存
http://stackoverflow.com/questions/26562033/how-to-set-apache-spark-executor-memory