hadoop hdfs 的压缩
当集群的hdfs增长速度很快时,需要对hdfs进行压缩,以减少硬件资金开销。
本文结合网上文章、已上某大型互联网公司生产环境同事经验,及本地测试验证,总结出此文。
背景 集群目前有57台机器,共1.2 PB数据,为了减少在硬件上的资金开销,需要对现有的数据进行压缩。
对load到hive前的 hdfs 文件,采取保留最近6个月内的数据,6-3个月内的数据 访问概率小,采用 bzip2 压缩
对load到hive里的 hdfs 文件,采取近乎全量lzo压缩
压缩算法是如何选择的?
首先,load hive前的数据,使用的较少,一般都是对hive表进行统计操作,但也有可能会有脱离 “正规套路” 的现象,例如外界有某个脚本或客户端,读取整个目录的情况,要尽量“浓缩”且“兼容”,只能bzip2了,可以压缩10倍空间,且可以有Linux命令,解压文件,以便check源文件。
其次,load hive里的数据,使用的较多,压缩率和处理速度是成反比的,因此需要选择一个适中的算法,lzo 和 snappy 都是合适的,但业界一般都用lzo,因此就选择了lzo。(其实如果有充分时间,可以对lzo和snappy做对比的)lzo 压缩后能少 60%-70%
1 2 3 4 5 压缩格式 split native 压缩率 速度 是否hadoop自带 linux命令 换成压缩格式后,原来的应用程序是否要修改 gzip 否 是 很高 比较快 是,直接使用 有 和文本处理一样,不需要修改 lzo 是 是 比较高 很快 否,需要安装 有 需要建索引,还需要指定输入格式 snappy 否 是 比较高 很快 否,需要安装 没有 和文本处理一样,不需要修改 bzip2 是 否 最高 慢 是,直接使用 有 和文本处理一样,不需要修改
生产环境适合用lzo么? 适合,但需要做处理。普通的hdfs文件是textfile,由于lzo不支持spilt,即一个文件不能被多个map并行处理,因此需要对textfile创建lzo索引,以支持spilt。但是生产环境,这种方式不适用,
每天每个hive表的分区目录下,都有很多文件,如果还要维护一个定时任务去创建索引,代价太大,也不方便。因此,我们可以用 sequeneceFile 的方式,用block做存储,就可以split的。
需要做的只有2步,首先,按分区lzo sequenceFile 压缩原始hive表的数据。其次,按sequenceFile创建hive表(STORED AS SEQUENCEFILE),再导入压缩后的数据。是不是更简单?
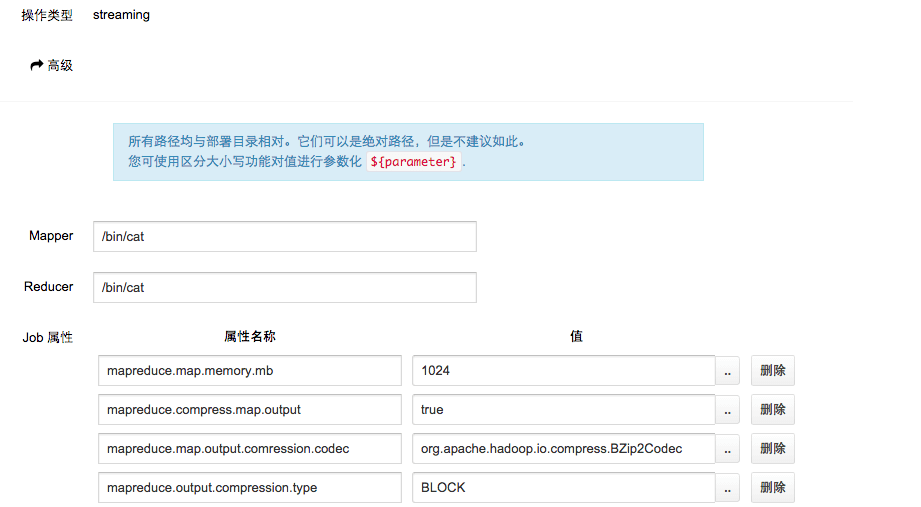
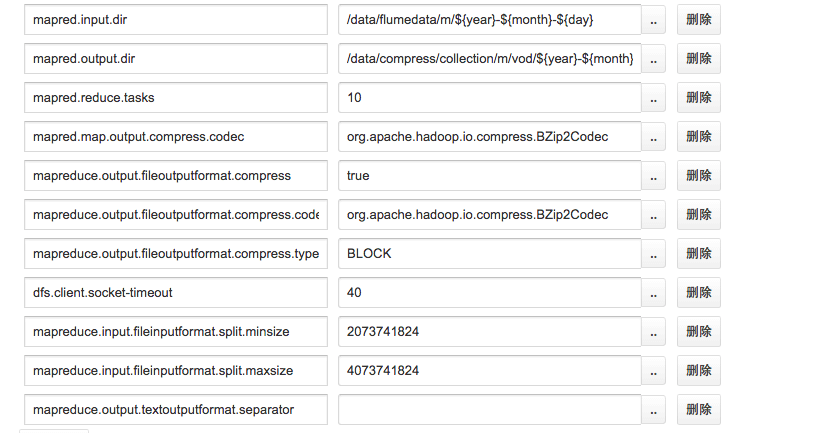
bzip2 压缩 建议用 hadoop streaming 的方式来做(下面是HUE中的配置),方便 代码少
lzo 环境准备 下载、解压并编译lzo包 (我的百度云备用地址 http://pan.baidu.com/s/1qW7N6ws
1 2 3 4 5 6 wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06 .tar.gz tar -zxvf lzo-2.06 .tar.gz cd lzo-2.06 export CFLAGS=-m64./configure -enable-shared -prefix=/usr/local /hadoop/lzo/ make && sudo make install
编译完lzo包之后,会在/usr/local/hadoop/lzo/生成一些文件,目录结构如下:
1 2 3 4 ls -l /usr/local /hadoop/lzo/ drwxr-xr-x 3 root root 4096 Mar 21 17 :23 include drwxr-xr-x 2 root root 4096 Mar 21 17 :23 lib drwxr-xr-x 3 root root 4096 Mar 21 17 :23 share
将/usr/local/hadoop/lzo目录下的所有文件打包,并同步到集群中的所有机器上。
在编译lzo包的时候,需要一些环境,可以用下面的命令安装好lzo编译环境yum -y install lzo-devel zlib-devel gcc autoconf automake libtool
编译安装Hadoop-LZO 下载Twitter hadoop-lzo
1 git clone https://github.com/twitter/hadoop-lzo.git
修改hadoop版本
1 2 3 4 5 <properties > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <hadoop.current.version > 2.3.0</hadoop.current.version > <hadoop.old.version > 1.0.4</hadoop.old.version > </properties >
编译,准备Hadoop lzo 环境
1 2 3 4 5 6 7 8 9 export CFLAGS=-m64export CXXFLAGS=-m64export C_INCLUDE_PATH=/usr/local /hadoop/lzo/includeexport LIBRARY_PATH=/usr/local /hadoop/lzo/libmvn clean package -Dmaven.test.skip=true cd target/native/Linux-amd64-64 tar -cBf - -C lib . | tar -xBvf - -C ~ cp ~/libgplcompression* $HADOOP_HOME /lib/native/ cp target/hadoop-lzo-0.4 .20 -SNAPSHOT.jar $HADOOP_HOME /share/hadoop/common/
在tar -cBf - -C lib . | tar -xBvf - -C ~命令之后,会在~目录下生成一下几个文件(即打包目录的东西并解压)
1 2 3 4 5 6 ls -l -rw-r--r-- 1 libgplcompression.a -rw-r--r-- 1 libgplcompression.la lrwxrwxrwx 1 libgplcompression.so -> libgplcompression.so.0.0 .0 lrwxrwxrwx 1 libgplcompression.so.0 -> libgplcompression.so.0.0 .0 -rwxr-xr-x 1 libgplcompression.so.0.0 .0
其中 libgplcompression.so 和 libgplcompression.so.0 是链接文件,指向 libgplcompression.so.0.0.0libgplcompression* 和 target/hadoop-lzo-0.4.20-SNAPSHOT.jar 同步到集群中的所有机器对应的目录。
配置Hadoop环境变量 1、在Hadoop中的$HADOOP_HOME/etc/hadoop/hadoop-env.sh加上配置 export LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib
2、在$HADOOP_HOME/etc/hadoop/core-site.xml加上如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <property > <name > io.compression.codecs</name > <value > org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec, org.apache.hadoop.io.compress.BZip2Codec </value > </property > <property > <name > io.compression.codec.lzo.class</name > <value > com.hadoop.compression.lzo.LzoCodec</value > </property >
3、在$HADOOP_HOME/etc/hadoop/mapred-site.xml加上如下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <property > <name > mapred.compress.map.output</name > <value > true</value > </property > <property > <name > mapred.map.output.compression.codec</name > <value > com.hadoop.compression.lzo.LzoCodec</value > </property > <property > <name > mapred.child.env</name > <value > LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib</value > </property >
将刚刚修改的配置文件全部同步到集群的所有机器上,并重启Hadoop集群(如果用CM来管理,则可以不用重启),这样就可以在Hadoop中使用lzo。
需要注意的几点 集群机器的环境变量
1.建立mkdir -p /usr/local/hadoop/lzo 文件夹存放library,并修改文件夹权限 chmod -R 777 /usr/local/hadoop/lzo
2.cloudera manager 的 hadoop 依赖的 本地库 路径 /usr/lib/hadoop/lib/native/ ,并把刚才编译得到的 lzo 本地库 放置 /usr/lib/hadoop/lib/native/libgplcompression*chmod 777,同理把编译好的 lzo jar 放置到 /usr/lib/hadoop/hadoop-lzo-0.4.20-SNAPSHOT.jar 并修改权限。
3.建立全局变量 ,不能设置到 .bash_profile里,因为此变量不跟用户挂钩.
1 2 echo "export LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib" >> /etc/profilesource /etc/profile
4.如果集群有 spark on yarn ,则还需要设置 spark 让其知道 lzo 环境
1 2 3 4 echo "export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH :/usr/lib/hadoop/lib/native/" >> /etc/profileecho "export SPARK_SUBMIT_LIBRARY_PATH=$SPARK_SUBMIT_LIBRARY_PATH :/usr/lib/hadoop/lib/native/" >> /etc/profileecho "export SPARK_CLASSPATH=$SPARK_CLASSPATH :/usr/lib/hadoop/hadoop-lzo-0.4.20-SNAPSHOT.jar" >> /etc/profilesource /etc/profile
5.如果是通过 HUE 查询 hive 压缩表数据,则需要配置 HiveServer2 的环境变量, 我是通过 cloudera manager 管理的,所以在 “HiveServer2 环境高级配置代码段” 里配置即可。附cdh issue 地址
1 LD_LIBRARY_PATH=/usr/local /hadoop/lzo/lib
压缩核心代码 利用 hadoop api 的方式 ,用 hadoop jar 来进行压缩,不用写 MR 更方便
pom.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 <?xml version="1.0" encoding="UTF-8"?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > com.test</groupId > <artifactId > hadoop-lzo</artifactId > <version > 0.0.1</version > <packaging > jar</packaging > <name > hadoop-lzo</name > <description > compress hadoop hdfs and reimport into hive table</description > <dependencies > <dependency > <groupId > com.test.lzo</groupId > <artifactId > hadoop-lzo</artifactId > <version > 0.4.20</version > <scope > system</scope > <systemPath > ${project.basedir}/hadoop-lzo-0.4.20-SNAPSHOT.jar</systemPath > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.3.0</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 2.3.0</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-client</artifactId > <version > 2.3.0</version > </dependency > <dependency > <groupId > org.slf4j</groupId > <artifactId > slf4j-api</artifactId > <version > 1.7.2</version > </dependency > <dependency > <groupId > log4j</groupId > <artifactId > log4j</artifactId > <version > 1.2.16</version > </dependency > <dependency > <groupId > org.slf4j</groupId > <artifactId > slf4j-log4j12</artifactId > <version > 1.7.2</version > <exclusions > <exclusion > <groupId > log4j</groupId > <artifactId > log4j</artifactId > </exclusion > </exclusions > </dependency > </dependencies > <build > <resources > <resource > <directory > src/main/resources</directory > <includes > <include > **/*</include > </includes > <filtering > true</filtering > </resource > </resources > <pluginManagement > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 2.3.2</version > </plugin > <plugin > <artifactId > maven-compiler-plugin</artifactId > <configuration > <source > 1.6</source > <target > 1.6</target > <encoding > UTF-8</encoding > </configuration > </plugin > </plugins > </pluginManagement > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-surefire-plugin</artifactId > <configuration > <skipTests > true</skipTests > </configuration > </plugin > <plugin > <artifactId > maven-source-plugin</artifactId > <version > 2.1</version > <configuration > <attach > true</attach > </configuration > <executions > <execution > <phase > compile</phase > <goals > <goal > jar</goal > </goals > </execution > </executions > </plugin > <plugin > <artifactId > maven-javadoc-plugin</artifactId > <version > 2.1</version > <configuration > <attach > true</attach > <encoding > UTF-8</encoding > </configuration > <executions > <execution > <phase > compile</phase > <goals > <goal > jar</goal > </goals > </execution > </executions > </plugin > <plugin > <artifactId > maven-assembly-plugin</artifactId > <version > 2.2-beta-5</version > <configuration > <appendAssemblyId > false</appendAssemblyId > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > <archive > <manifest > <mainClass > com.test.Main</mainClass > </manifest > </archive > </configuration > <executions > <execution > <id > make-assembly</id > <phase > package</phase > <goals > <goal > assembly</goal > </goals > </execution > </executions > </plugin > </plugins > </build > </project >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataInputStream;import org.apache.hadoop.fs.FileStatus;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.BytesWritable;import org.apache.hadoop.io.IOUtils;import org.apache.hadoop.io.SequenceFile;import org.apache.hadoop.io.Text;import org.apache.hadoop.io.compress.CompressionCodec;import org.apache.hadoop.util.ReflectionUtils;private static final String LZO = "com.hadoop.compression.lzo.LzoCodec" ;private static String FS = "hdfs://localhost:8020" ;private static void compress (String inputPath, String outputPath) Configuration conf = new Configuration(); conf.set("fs.defaultFS" , FS); FSDataInputStream inputStream = null ; SequenceFile.Writer writer = null ; try { FileSystem fs = FileSystem.get(conf); Path input = new Path(inputPath); inputStream = fs.open(input); FileStatus stat = fs.getFileStatus(input); BufferedReader buff = new BufferedReader(new InputStreamReader(inputStream)); BytesWritable EMPTY_KEY = new BytesWritable(); Path seqFile = new Path(outputPath); CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(Class.forName(LZO), conf); writer = SequenceFile.createWriter(conf, SequenceFile.Writer.file(seqFile), SequenceFile.Writer.keyClass(BytesWritable.class), SequenceFile.Writer.valueClass(Text.class), SequenceFile.Writer.compression(SequenceFile.CompressionType.BLOCK, codec)); String str = "" ; System.out.println("begin" ); while ((str = buff.readLine()) != null ) { writer.append(EMPTY_KEY, new Text(str)); } System.out.println("done" ); } catch (Exception e) { e.printStackTrace(); } finally { IOUtils.closeStream(inputStream); IOUtils.closeStream(writer); } }
注意 SequenceFile 是 key-value 型格式,即使 key 不输出任何值,也会 “占位”,所以压缩完文件 可以利用下面命令 看一下,第一列会有一列空占位
1 hadoop fs -text <yourlzofile> | head
判断一个文件是否是 SequenceFile , 可以新建 hive 表 store as SEQUENCEFILE ,然后 类似这样 load 进去
1 load data inpath 'hdfs://localhost:8020/data/xiaolong.yuanxl/lzo/' overwrite into table yxl_test partition(b='pcc' ,year='2015' ,month='06' ,day='17' );
测试结果 数据准备:
t1 数据文件 300M 压缩后 118M
t2 数据文件 800M压缩后 305M
hql 测试示例:
1 2 3 4 5 select * from t2 left outer join t1 on t2.uid=t1.uid group by t2.uuid ,t2.ip;select count (distinct t2.deviceid) from t2 left outer join t1 on t2.uid=t1.uid group by t2.deviceid,t2.uuid ,t2.ip ;
测试结果:
1 2 3 4 5 6 7 8 表情况 HQL Mapper Time 均压 1 2 Time taken: 83.887 seconds Fetched: 920746 row(s) 未压t1 1 3 Time taken: 78.108 seconds Fetched: 920746 row(s) 均未压 1 6 Time taken: 98.233 seconds Fetched: 920746 row(s) 均压 2 3 Time taken: 100.466 seconds Fetched: 606651 row(s) 未压t1 2 3 Time taken: 91.218 seconds Fetched: 606651 row(s) 均未压 2 5 Time taken: 95.349 seconds Fetched: 606651 row(s)
注意:数据文件压缩完后,尽量大一些,hadoop 2.3.0 600M的hdfs文件才会启动3个mapper,当然这个也跟环境有关系。
参考资料:
感谢同事 张龙 分享并指导经验,以至于少走很多弯路。