install hadoop on local
更新日期:
介绍如何在本机搭建一个单机伪分布式的hadoop 1.2.1 ,用于学习
环境准备
1.一台有linux系统的电脑,ubuntu、centos均可。在物理机windows上装虚拟机linux也行至少分配1G以上内存,便于启动、调试。
2.安装java(版本1.6以上),下载hadoop-1.2.1-bin.tar.gz
1 | xiaolongyuan@xiaolongdeMacBook-Air .ssh$ java -version |
3.配置ssh(可以参考这里)
配置
1.解压hadoop-1.2.1-bin.tar.gz到文件夹中,并在此文件夹下,新建 tmp 文件夹,然后修改几个文件
1 | <property> |
1 | <property> |
1 | <property> |
(注:由于master文件和slave文件都是 localhost,因此不用修改)
2.格式化namenode的hdfs
1 | cd hadoop-1.2.1/bin |
3.修改 conf/hadoop-env.sh,向里面添加JAVA_HOME
1 | # The java implementation to use. Required. |
4.启动hadoop,jps检查hadoop进程是否启动
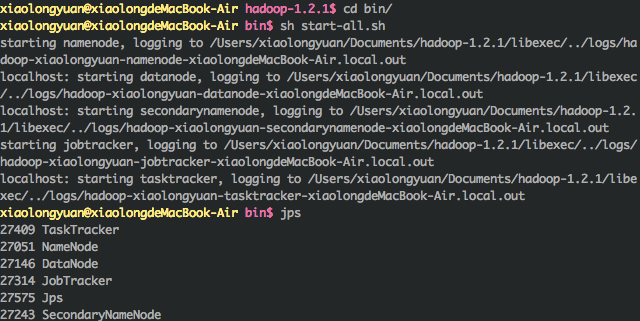
5.再访问一下web界面,看是否可以正常访问
